Quanta memoria utilizza il mio Linux?
by Pasquale
Ho di recente installato Zorin OS 17, la distribuzione Linux dei fratelli Zorin.
Questa versione, rilasciata lo scorso 20 dicembre, ha un desktop Gnome, mentre arriverà solo nei prossimi mesi quella con XFCE, più leggera e quindi più adatta al mio Asus E210 che ha solo 4 GB di ram. Avevo quindi alcuni dubbi iniziali sulle prestazioni, in gran parte dissipati da questi primi giorni di utilizzo.
Per valutare in modo più obiettivo quando il carico di applicazioni comincia a mettere in crisi l'E210, ho rispolverato un paio di script preparati qualche tempo fa, per misurare l'occupazione della memoria e delle aree di swap con un Xubuntu (la distribuzione Linux con desktop XFCE che ho utilizzato appena prima di Zorin OS 17).
Le aree di Swap
Zorin OS 17 configura all'installazione un'area di swap su disco pari alla dimensione di memoria ram disponibile.
In questa area finiscono le pagine di memoria fisica non utilizzate di recente, quando l'esecuzione delle applicazioni richiede la disponibilità di altra memoria.
È come se la memoria fisica venisse estesa a 4 + 4 = 8 GB. Naturalmente, per poter essere utilizzate, le pagine spostate nell'area swap devono essere riportate nella memoria ram, eventualmente spostando altre pagine nello swap.
È intuibile che, sotto carico, si può generare un andirivieni di pagine tra RAM e swap, con un impatto sensibile sulle prestazioni della macchina.
Un parziale sollievo viene dalla creazione dello zswap, un'ulteriore area di swap ricavata nella memoria ram. La dimensione consigliata per l'area di zswap è di circa la metà della dimensione della memoria ram, quindi nel mio caso 2 GB.
Può sembrare un non sense spostare pagine all'interno della memoria. Ma c'è un beneficio, che viene sia dal ridotto numero di operazioni su disco, più lente della scrittura in ram, sia dalla compressione con cui le pagine vengono memorizzate nell'area di zswap.
Utilizzando una compressione spinta (lz4 / z3fold) si può arrivare a un rapporto di almeno 2.5.
Questo vuol dire che, quando i 2 GB dello zswap sono completamente occupati, il loro reale ingombro è minore di 2 GB / 2.5 = 0.8 GB.
La raccolta dei dati di misura
Per raccogliere i dati di occupazione della memoria e degli swap mi avvalgo di qualche comando shell e due script bash creati ad hoc, che riversano i dati raccolti in file di tipo csv.
I comandi:
- free (mostra l'occupazione della memoria ram e quella totale degli swap)
- swapon (mostra l'occupazione dei singoli swap)
- sudo cat /sys/kernel/debug/zswap/stored_pages (restituisce il numero di pagine memorizzate nello zswap)
- sudo cat /sys/kernel/debug/zswap/pool_total_size (restituisce l'occupazione dello zswap, dato già fornito da swapon)
Le due ultime misure, conoscendo la dimensione di una pagina (4096 bytes) consentono di risalire al rapporto di compressione effettivo dello zswap al momento della misura.
Gli script
Il primo script (newstats.sh) deve essere lanciato in due istanze, in due diverse finestre di terminale:
- newstats.sh -a -h
questo comando stampa nel file csv una prima riga di intestazione e poi rileva ogni 5 secondi l'occupazione di memoria e del totale degli swap, dello swap su disco e dello zswap;
per fermarlo basta digitare Control C nel terminale; - newstats.sh
qui viene fatta una sola misura, preceduta dalla richiesta di un input da tastiera, il cui valore verrà poi inserito nel record dati del file csv;
viene lanciato prima di ogni passo della lista di carico, inserendo da tastiera la descrizione del passo da effettuare.
#!/bin/bash
#
# lancio dello script:
# ./stats.sh -a -h : stampa header, una misura ogni 5 sec, interruzione via ^c
# ./stats.sh -a : una misura ogni 5 sec, interruzione via ^c
# ./stats.sh -h : stampa header, una sola misura
# ./stats.sh : una sola misura
#
if [ "$1" == "-a" ] || [ "$2" == "-a" ]
then auto="yes"
else auto="no"
fi
if [ "$1" == "-h" ] || [ "$2" == "-h" ]
then hdr="yes"
else hdr="no"
fi
if [ "$auto" == "yes" ]
then
commento="auto"
echo interrompi l\'esecuzione con ^C
else read -p "inserisci il commento: " commento
fi
if [ "$hdr" == "yes" ]
then printf "Time\tMem used\tBuffCache\tSwap used\tSwap_file\tZSwap\tcomment\tevent\n" |
tee -a log_swap.csv
fi
#
while :
do
used=$(free | awk 'BEGIN {FS=" "; OFS="\t"}
{if ($1 == "Mem:") print $3 "-" $5}
{if ($1 == "Swap:") print "-" $3}
')
MemUsed=$(echo $used | cut -f1 -d-)
Buffcache=$(echo $used | cut -f2 -d-)
SwapUsed=$(echo $used | cut -f3 -d-)
#
swaps=$(swapon -s | awk 'BEGIN {FS=" "; OFS="\t"}
{if ($1 == "/swapfile") print $4}
{if ($1 == "/dev/zram0") print "-" $4}
')
Swapfile=$(echo $swaps | cut -f1 -d-)
Swapzram=$(echo $swaps | cut -f2 -d-)
if [ "$auto" == "yes" ]
then
event=""
else
event=$MemUsed
fi
#
printf "%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\n" "$(date +"%T")" "$MemUsed" "$Buffcache" "$SwapUsed" "$Swapfile" "$Swapzram" "$commento" "$event" |
tee -a log_swap.csv
if [ "$auto" != "yes" ]
then
break
else
sleep 5
fi
doneIl secondo script, molto più semplice, rileva due valori relativi allo zswap: numero di pagine memorizzate e occupazione totale.
#!/bin/bash
#
pages=$(sudo cat /sys/kernel/debug/zswap/stored_pages)
poolsize=$(sudo cat /sys/kernel/debug/zswap/pool_total_size)
compress=$(echo "scale=3; $pages * 4096 /$poolsize;" | bc)
printf "%s\t%s\t%s\t%s\n" "$(date +"%T")" "$pages" "$poolsize" "$compress" | tee -a compressione.csvUn esempio di dati raccolti
I dati raccolti dai due script vengono memorizzati in due file distinti, di tipo csv, con il carattere TAB utilizzato come separatore.
Questo è un esempio di record nel file log_swap.csv:
Time Mem used BuffCache Swap used Swap_file ZSwap comment event 08:26:41 1079752 169428 0 0 0 auto 08:26:46 1107060 169396 0 0 0 auto ... 08:27:32 1118884 179176 0 0 0 auto 08:27:37 1117616 171208 0 0 0 auto 08:27:37 1117740 171192 0 0 0 lancio esplora risorse e apro la lista di carico con gedit 1117740 08:27:42 1130852 182832 0 0 0 auto 08:27:47 1148336 182088 0 0 0 auto
L'ultimo campo del record, event, viene inserito in presenza di un commento, e riporta il valora del primo campo, Mem used. Questo consente di avere una visione chiara sul grafico dei dati del momento in cui è stato inserito il commento, come si vede dai tic rossi nell'esempio:
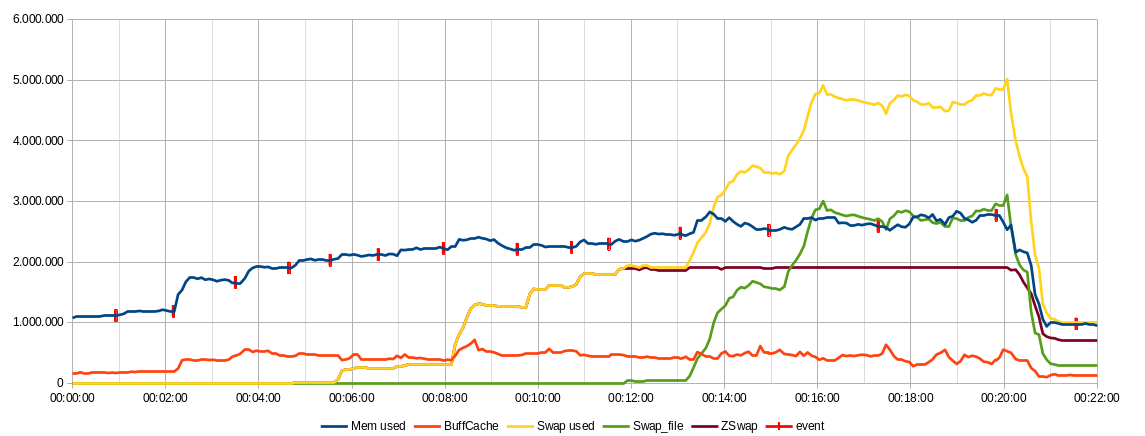
Il grafico verrà analizzato nel post successivo.
L'output del secondo script è più semplice. Ecco un estratto dal file compressione.csv:
21:09:35 3466 2674688 5.307
Qui ha vinto la pigrizia, non c'è nessuna intestazione, ma la struttura del record è molto semplice: ora - numero di pagine - occupazione - compressione.
La campagna di misura
Con gli script a disposizione non resta che effettuare la campagna di misure:
- preparare una lista di applicazioni da lanciare una dopo l'altra;
- a sistema appena avviato, eseguire i passi della lista;
- raccolti i dati, analizzarli con un foglio di calcolo (LibreOffice Calc oppure Excel).
Il seguito al prossimo post!